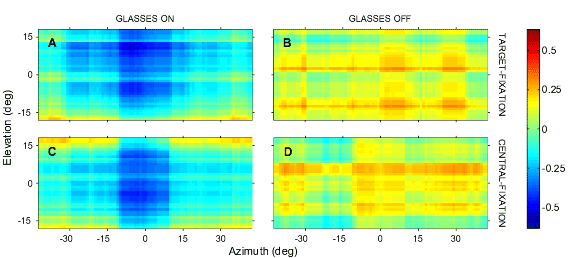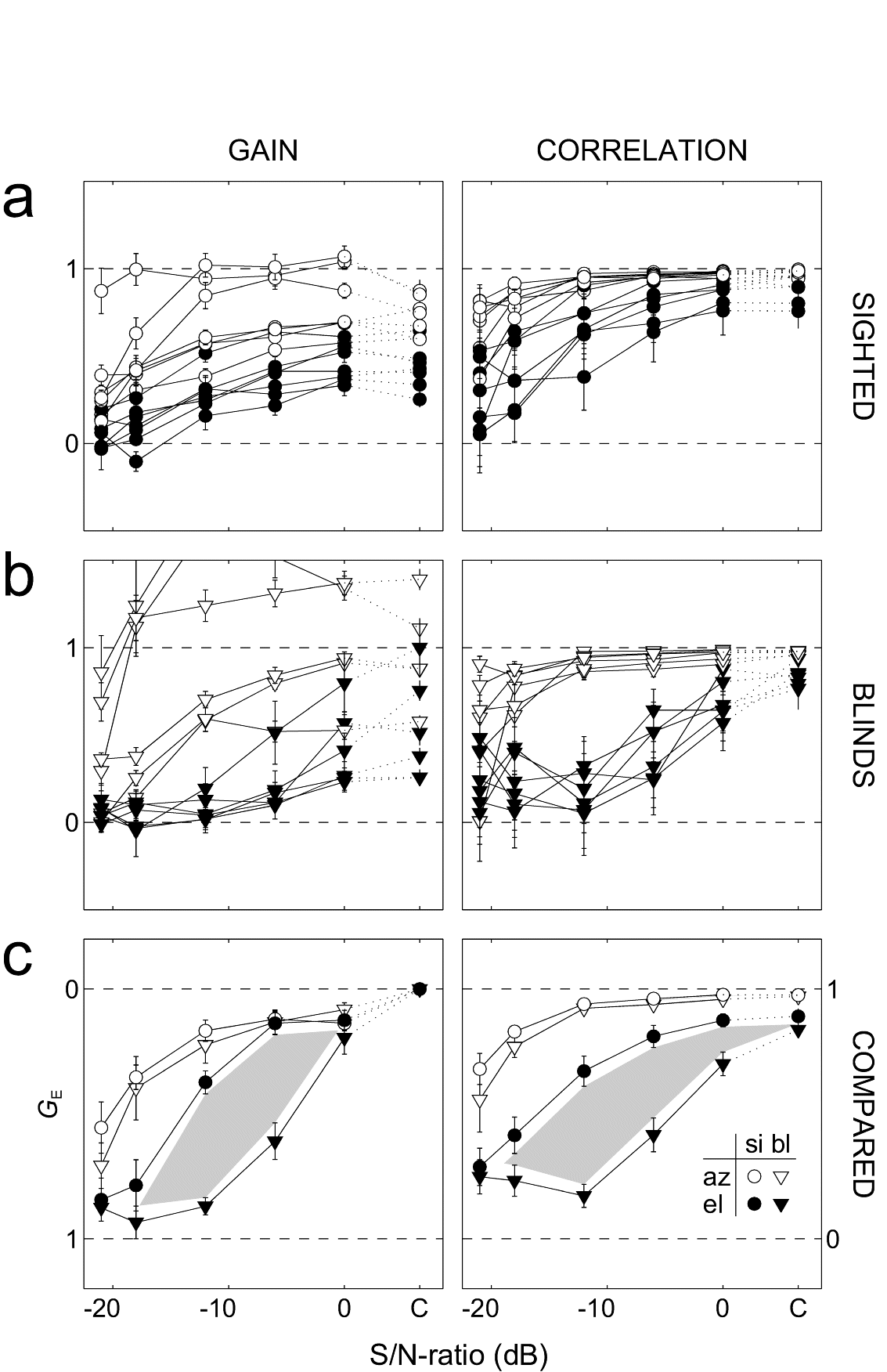
(A,B) show the raw regression results (gain and correlation) per subject; open symbols: azimuth, closed symbols: elevation. Circles: sighted. Triangles: blind.
Panel (C) shows the results after normalization of the regression parameters, in order to get rid of the variability in baseline behavior (and allowing for averaging across subjects).
The blind and sighted were indistinguishable when comparing their azimuth localization (C, open symbols). However, in elevation the blind were clearly impaired when compared with the sighted (closed symbols).
Grey area within the two elevation curves corresponds to a difference of at least four standard deviations. At the extremes (no background noise, and at -21 dB S/N ratio) the two groups were the same. For the intermediate S/N ratios, however, the blind clearly performed much worse. As soon as background noise sets in, the blind are almost incapable of localizing elevation.
We conclude that elevation localization in the frontal hemifield requires training by vision. However, an intact visual system is not mandatory for learning to localize stimulus azimuth.